


Understanding Amazon Bedrock Knowledge Bases: Key Points
Deep dive


Article complexity: Intermediate. Target audience: managers and engineers
Introduction
AWS reInvent 2023 was full of Generative AI announcements, one of them being AWS Amazon Bedrock Knowledge Bases. This article will tell the story of starting an internal production-ready AI project in a fictional company, specifically retrieval-augmented generation (RAG). Simply put, your AI assistant is powered by your company's knowledge captured in different forms like PDFs, articles, whitepapers, etc.
Telling the story, I assume you 1) already played with one of the generative AI chatbots like ChatGPT, MS Bing Copilot, or Google Bard. I hope you had a chance to 2) try state-of-the-art models like GPT-4 or Claude 2.1. The last assumption is you know 3) "specific data cut off" of Large Language Models (LLMs). They have knowledge limited by concrete date.
An idea for AI-powered Assistant

The story starts with the fictional company called "ZeHouse Solutions" (ZHS), which has been producing hubs to host smart-home and smart-office solutions since the 2000s when Zigbee was an early days protocol. For the last two decades, the company has been using its own data centre for software development and partner network to deliver its product to end customers.
An essential feature of ZHS hubs was their offline mode. There is no need for Cloud connectivity to set up and run your hub. It's your responsibility to download firmware and upgrade your devices. Also, all custom configuration was the responsibility of integrators or end customers.
In 2024, ZHS engineers saw the potential of generative AI to help their customers configure hubs. As a well-established company with hundreds of PDFs and documentation for different hub features developed over 20 years, it was challenging to master CLI and the web interface.
So, the engineers played with proof of concept for generative AI powred assitent and are ready for the next step to talk to their managers...
Engineers + Managers = Shared Understanding of GenAI product
Before deep-diving into discussions about the architecture, budget, responsibility, and outcomes of engineers offered a mental model of the AI system based on a shiny new book "Generative AI on AWS" by Chris Fregly, Antje Barth, and Shelbee Eigenbrode (O’Reilly). Copyright 2024 Flux Capacitor, LLC, Antje Barth, and Shelbee Eigenbrode, 978-1-098-15922-1.
So guys! Let's map typical components of an AI system to our trainee program activities!
According to Chapter 9 of the book, we have the following components of the system: 0) Infrastructure, 1) Generative models and supporting machine learning (ML) models, 2) Information sources, 3) External systems, 4) Tools and frameworks, 5) Monitoring and logging, 6) Generated outputs and feedback, 7) Operational tooling.
I'll skip the Infrastructure and Operational tooling blocks and jump straight to Generative models. They will be our trainees :)

We have people, but we must empower them with our documentation = Information sources. We will imagine information sources as our company library!

What is the next block on the list? External systems? What is it? These are a lot of questions about our complex systems, but not all can be answered by reading our documentation; we need experts! Yes! External systems are our experts.

We have trainees with access to our documentation library and experts to find the best possible answers for customer questions. What we are missing are Tools and frameworks to get work done.

And "Monitoring and logging" to understand progress and whether our team needs help with their job.

Oh, some of the engineers said there are many moving parts! Let's show the managers our model of trainees using laptops to access monitored documentation libraries and chat with experts to Answer the questions. And here comes the most important part: Who will assess the quality of the answers? Managers? No! :)
Your user community and partners know questions and the best answers to them. Building and working with your community is the key to success!

Note. Dear reader please note that generative AI is not capable of mimicing the mechanism of human brain. It's litteraly predicts words when asnwering your questions.
Offered here model is only an illustration of all moving parts that you need to combine together in order to offer generative AI powered product. This model is targeted for less technical colleguas, to show them the complexity of a product and roles that GenAI project/product requires.
The AI assistant is ready for production. Do we need to panic?

Our small team of enthusiastic engineers came with our comics mental model to the meeting with managers and got approval. Hooray! Or not? How do you make a proof of concept product from Jupiter Lab + LangChain, even for internal use?
And here comes the book we mentioned: "Generative AI on AWS"! We can use AWS Bedrock services to build our backend E2E. Let's try it using the same moving parts model!
The Challenge
The primary challenge was to demonstrate the effectiveness of RAG in a real-world application. The team aimed to build a system that leveraged the vast amount of information in PDF documentation and provided contextually relevant and accurate information in a conversational AI setting. They needed a platform seamlessly integrating various components, including data storage, a vector database for efficient retrieval (library together with experts), and a hosted LLM (trainees).
The Solution: AWS Bedrock
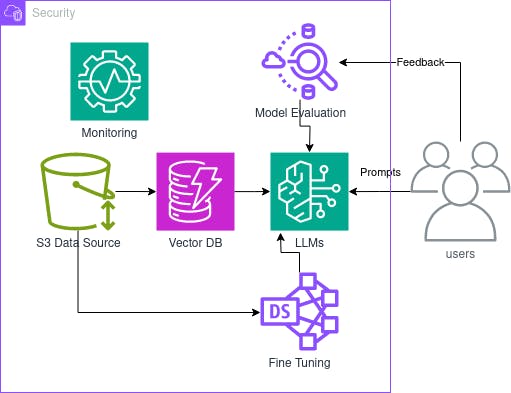
AWS Bedrock emerged as the ideal solution for this challenge. It provided a comprehensive environment facilitating easy experimentation with advanced AI concepts like RAG. The key features that made AWS Bedrock an excellent choice for this project included:
Out-of-the-Box Data Import from S3: AWS Bedrock allowed the team to import their PDF documentation directly from Amazon S3. This feature streamlined the process of feeding data into the system, which was crucial for feeding the RAG pipeline. Knowledge base for Amazon Bedrock Service
Vector Database Integration: Integrating a vector database was essential for the RAG setup. It enabled efficient storage and retrieval of information, a backbone of the RAG system. The vector database within AWS OpenSearch serverless ensured that RAG's retrieval component was fast and accurate.
Hosted Large Language Model (LLM): AWS Bedrock provided access to a state-of-the-art LLMs garden. These models served as the foundation for generating responses, while the external data fetched from the vector database enriched these responses with relevant information. Also, we can choose which model is better for our AI assistant, including fine-tuned models.
Model Evaluation Tools: The platform offered comprehensive model evaluation tools. These tools were essential for assessing the performance of the RAG system, allowing the team to measure the accuracy, relevance, and coherence of the responses generated by the LLM and to ensure that the integration with the vector database was functioning optimally.
Fine-Tuning Capabilities: AWS Bedrock enabled the team to fine-tune the LLM to suit specific use cases. This customization was crucial for tailoring the model's responses to the nature of the dataset's smart home terminology and the project's particular requirements. By fine-tuning the LLM, the team could optimize its performance and improve the relevancy of the generated content.
Robust Security Measures: Security is paramount when dealing with large datasets and AI models. AWS Bedrock provided robust security measures to protect data and model integrity. This included secure data handling practices, encryption, and compliance with industry-standard privacy regulations, ensuring that the team's RAG system was efficient and secure.
Comprehensive Monitoring: Finally, AWS Bedrock offered extensive monitoring capabilities. This feature allowed the team to track the system’s performance in real-time, promptly identify any issues, and ensure that the system ran smoothly and efficiently. Monitoring tools were especially important to monitor the system's interaction with the vector database and the LLM’s response generation.
The Experimentation Process
The team started by importing a curated dataset from S3 into the vector database. This dataset was designed to represent documentation about the smart home and office hub's range of knowledge that could be useful for the LLM while answering complex configuration questions from both the internal support team and later from the customers directly.
Next, they integrated the LLM with the vector database. The LLM was configured to query the database dynamically during the generation process, fetching relevant information to augment its responses. For this one, they used RetrieveAndGenerate AWS Bedrock endpoint .
Results and Insights
The proof of concept was a resounding success. The RAG system demonstrated a remarkable ability to provide contextually relevant and detailed answers. For instance, when asked about CLI commands to configure time synchronization using the NTP server, the system was able to pull recent data from the vector database, providing responses that were not only accurate but also up-to-date.

Conclusion
The introduction of AWS Bedrock has given ZeHouse Solutions an effective tool to develop a retrieval-augmented generation (RAG) system. This AI-powered assistant uses the company's extensive documentation to provide accurate and contextually relevant responses to complex configuration questions. The RAG system's success demonstrates the potential of generative AI in enhancing customer service and internal support. Looking forward, it is clear that AWS Bedrock's capabilities will continue to be instrumental in the evolution and improvement of AI-assisted services.
Note. AI (OpenAI DALL-E engine) generates all images in this article.